The author is a Senior Data Engineer in Eucloid. For any queries, reach out to us at: contact@eucloid.com
Commanding Big Data on Databricks: Optimised Pipeline Runtime from 12.5 Hours to 2 Hours

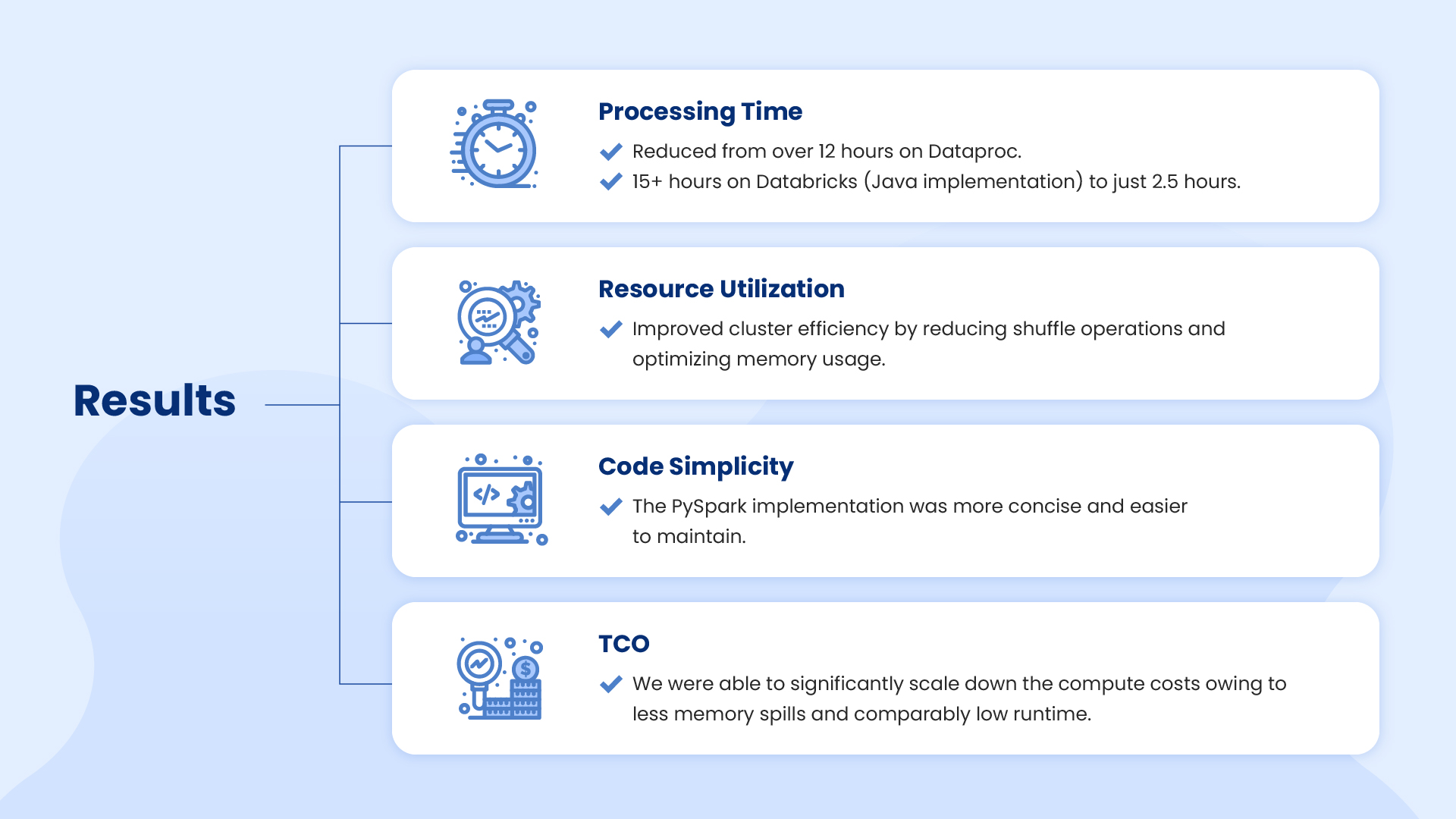
This performance bottleneck was impacting their ability to deliver timely insights to their customers. Even with 15 hours of runtime, attempting to execute the identical Java code on Databricks proved ineffective.
This led our team to optimise the pipeline by redesigning it in PySpark, resulting in a catching reduction in execution time to under 2.5 hours!
Problem Overview
The original pipeline had several issues that contributed to its inefficiency:
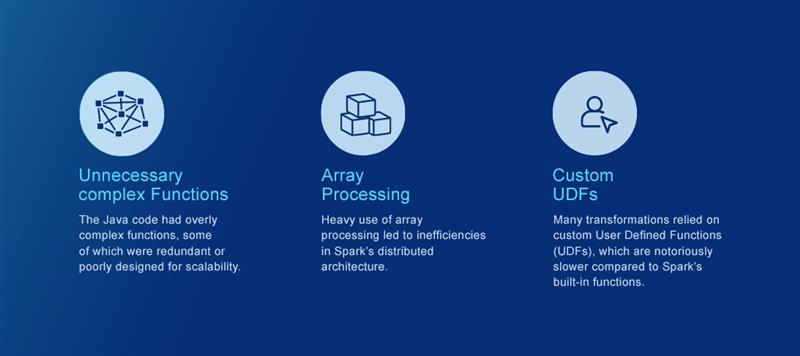
- Unnecessary Complex Functions: The Java code had overly complex functions, some of which were redundant or poorly designed for scalability.
- Array Processing: Heavy use of array processing led to inefficiencies in Spark’s distributed architecture.
- Custom UDFs: Many transformations relied on custom User Defined Functions (UDFs), which are notoriously slower compared to Spark’s built-in functions.
When attempting to run this code on Databricks, it became evident that it was not optimized for the platform’s strengths. Without a significant rewrite, the pipeline would remain a bottleneck.
Understanding the Business Requirements
Before getting into optimisation, we spent time studying the business logic driving the transformations. This phase was critical to ensure that the revised code met all functional requirements while increasing performance. The key tasks involved cleaning and standardising input data:
- Aggregating huge datasets
- Utilizing bespoke business rules for data enrichment
Optimization Approach
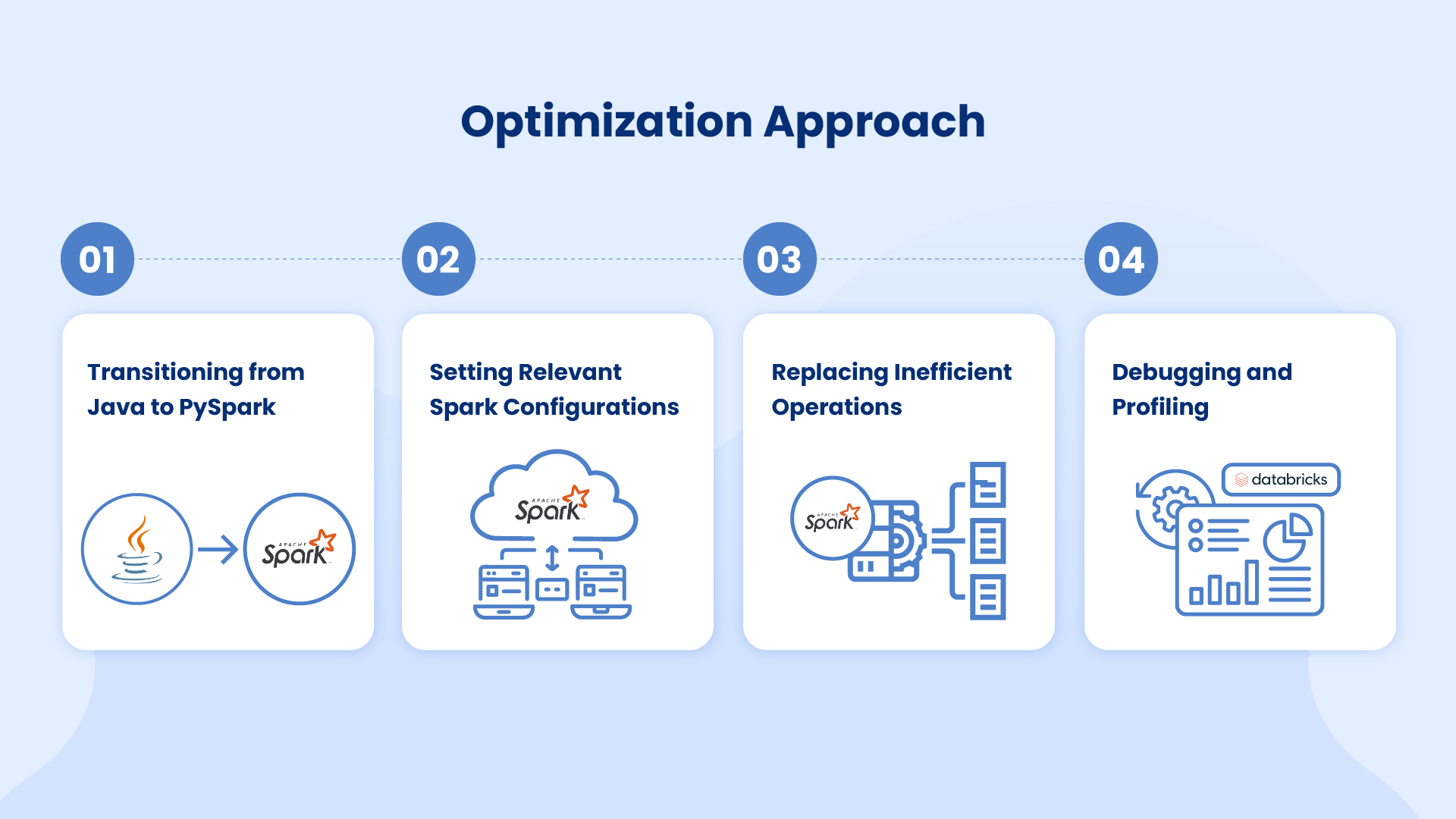
1. Transitioning from Java to PySpark
While Java is a powerful language, PySpark provides a more concise syntax and better integration with Databricks’ ecosystem. By leveraging PySpark,we:
- Reduced code complexity, making it easier to maintain.
- Leveraged advantage of Databricks’ built-in optimizations for Python workloads.
2. Setting Relevant Spark Configurations
Tuning Spark configurations was critical to handle the large dataset efficiently. Some key settings included:
- spark.executor.memory and spark.executor.cores: Adjusted to maximize resource utilization on the cluster.
- spark.sql.shuffle.partitions: Set to an appropriate number based on the dataset size to optimize shuffle operations.
- spark.dynamicAllocation.enabled: Enabled to ensure efficient resource allocation.
3. Replacing Inefficient Operations
a. Removing Unnecessary Functions:
The Java code included redundant computations and excessive intermediate steps. By streamlining the transformations we reduced the overall computational load.
b. Using Window Functions
Array processing in the Java code was replaced with Spark’s window functions.
For example, calculating cumulative sums and rankings over partitions became significantly faster using window specifications
c. Replacing UDFs with Built-in Functions
Custom UDFs in the Java code were rewritten using PySpark’s built-in functions, which are optimized for distributed computation.
For instance, instead of a UDF to calculate the median of an array, we used percentile_approx on partitions. Built-in functions not only improved performance but also enhanced code readability.
4. Debugging and Profiling
Throughout the rewrite process, we utilised Databricks’ Spark UI to profile the pipeline and identify bottlenecks. This iterative debugging process helped fine-tune the optimizations.
Results
The optimized PySpark pipeline achieved the following:
Migrating and optimising a legacy pipeline is a challenging but rewarding task. By rewriting the Java Spark code in PySpark and applying targeted optimisations, we were able to unlock the full potential of Databricks for this use case. Always strive to balance performance, maintainability, and scalability when migrating or building new pipelines.
Posted on : March 25, 2025
Category : Data Engineering
About the Authors

Harsh Bhandari
 LinkedIn
LinkedIn