The author is a Senior Data Engineer in Eucloid. For any queries, reach out to us at: contact@eucloid.com
Sessionization in Real-time Using Structured Streaming

Today, decisions are made not in hours or days, but in milliseconds. Businesses don't just react to change but anticipate and shape it. Organizations must be able to rapidly assess and act on information as it becomes available to capitalize on opportunities, address problems, and customize consumer experiences. This is the promise of real-time data processing, something that's redefining the very fabric of corporate strategy and operations. In fact, the transition from batch processing to real-time data processing has already enabled businesses to streamline operations, improve customer satisfaction, and enhance decision-making.
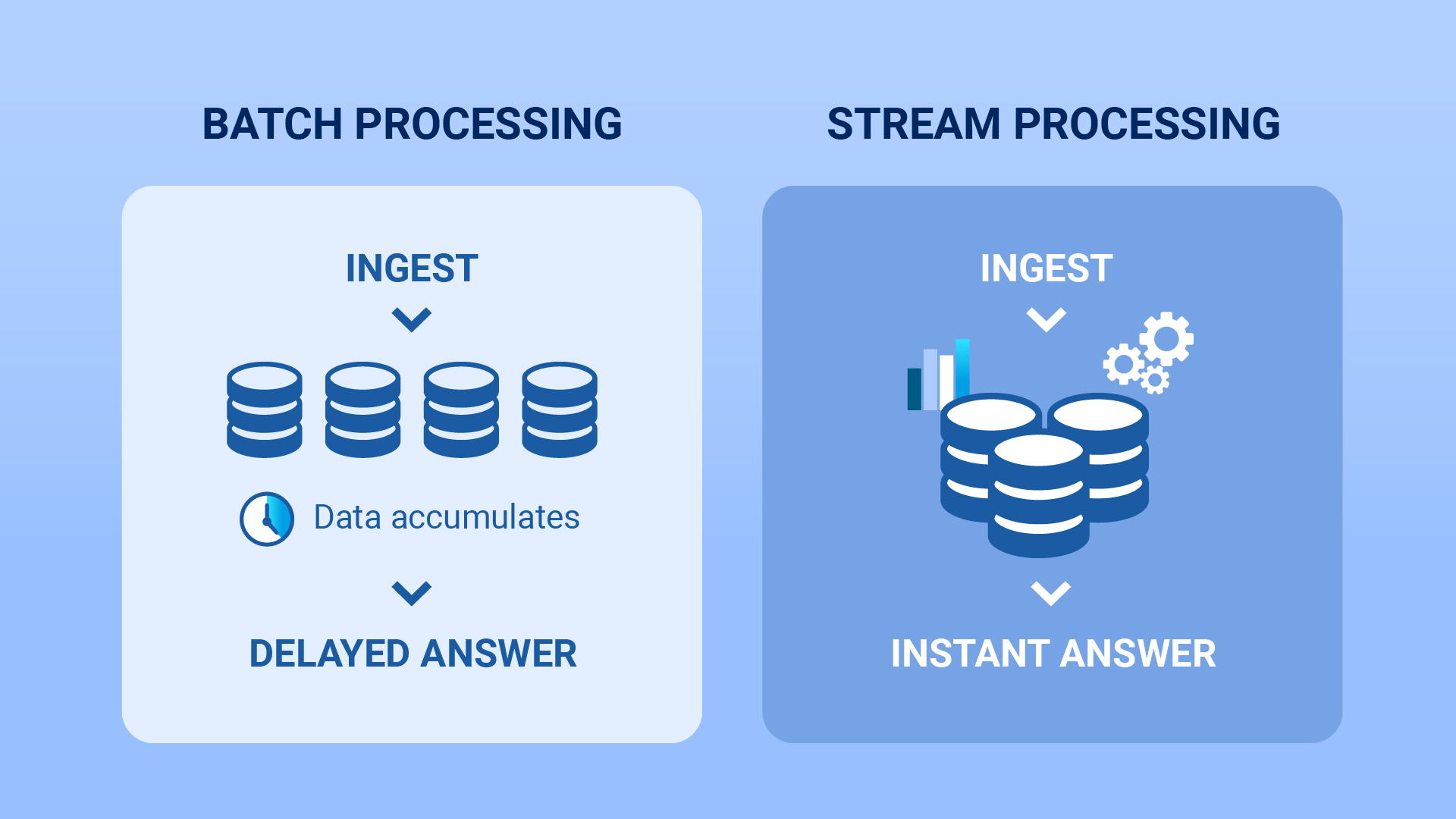
At its core, real-time data processing, also known as stream processing, is the science of collecting, analyzing, and acting on data when it's generated. However, to harness this power, businesses need more than just data; they need a robust infrastructure capable of handling sub-second latency, ensuring that the journey from raw data to actionable insight is as swift as thought itself.
Use-cases for structured streaming
Take the EV sector for instance – with the transition towards electric vehicles, the demand for real-time sessionization has become evident. Valid sessions for charging, parking, and usage of EVs must be tracked and processed in real time to provide essential updates and notifications to stakeholders. With data being available in real time, decision-makers can analyze it and take immediate action. For instance, an EV charging station can dynamically adjust charging rates based on current grid load, ensuring efficient utilization of resources and an optimal user experience. A parker can receive an alert just before their session expires, avoiding fines and frustration. Real-time processing leads to operational efficiency as it enables businesses to allocate resources and manpower on the fly based on current needs.

Organizations were previously using traditional data processing methods such as pandas DataFrame to process data. However, with the increasing volume and velocity of data, traditional data processing techniques have become inadequate to meet the market's need for real-time action. This is where Spark DataFrame comes into play. Spark DataFrame allows for parallel processing of data streams, making it possible to process large volumes of data in real time.
The transition from Batch to Stream
Migration from batch to stream can be challenging, especially when there are aggregations involved which are not supported in structured streaming due to multiple logical restrictions. Streaming pipelines require new techniques for data aggregation, joins, and handling streaming bottlenecks. There is also a need to optimize costs and handle late arriving dimensional data.
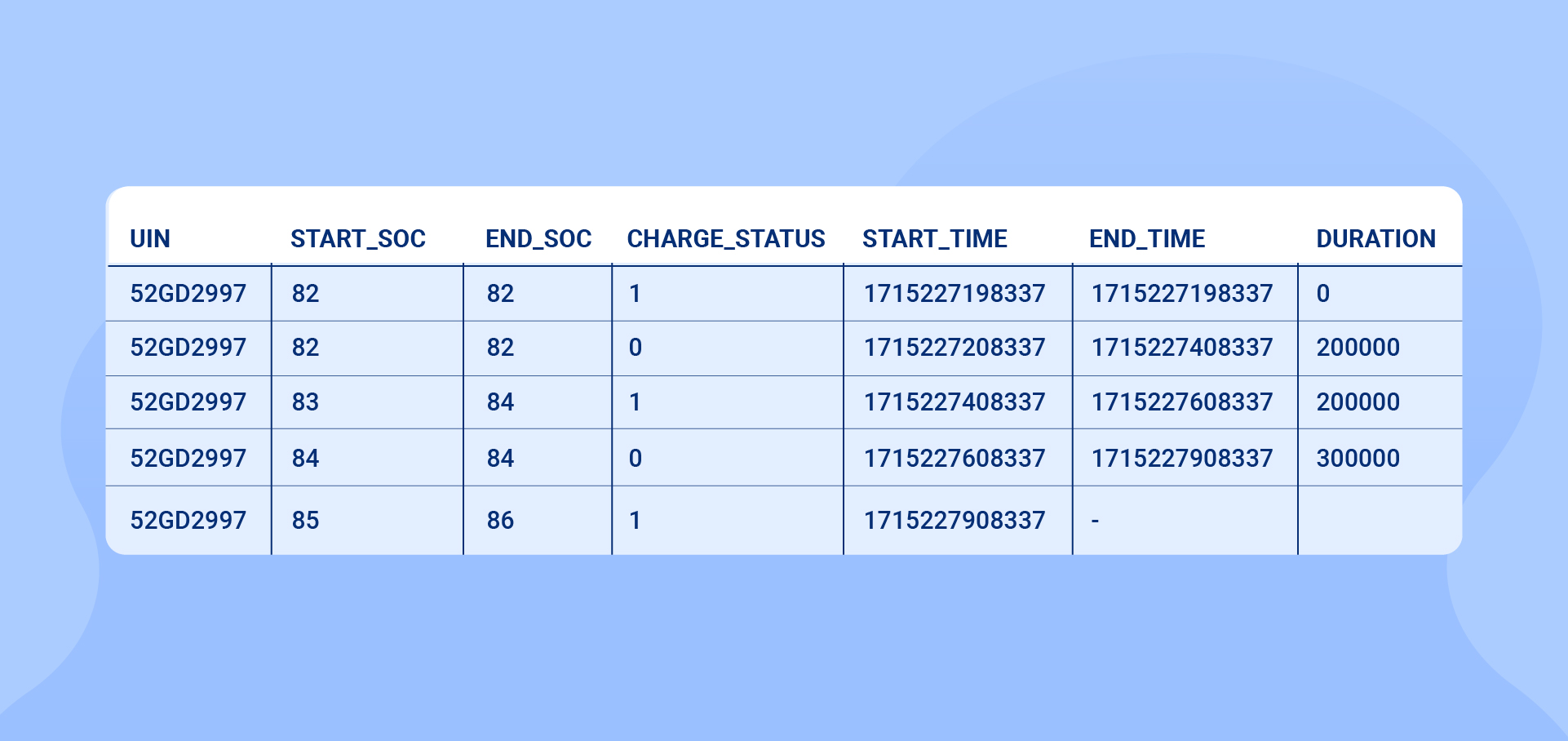
Let's take the example of Company DroneX that manufactures drones for agricultural purposes. These mega drones are charged during valid charge sessions of at least 30 minutes. This ensures that the drones have enough power to carry out the designated tasks effectively. However, to optimize the performance of these drones, there is an additional requirement of a break of 5 minutes during the charging session. During this break, the charge status is monitored and if it remains false for longer than the specified time limit, the session is terminated.
DroneX has incorporated pandas DataFrame in their data processing system to record and track the charge sessions. However, despite its ability to handle large amounts of data efficiently, latency and process serialization pose major challenges for near real-time notification of users to switch charge modes. This could potentially result in longer process times and delays in charge status updates, ultimately affecting the overall performance of the drone.
The Solution: Streaming Data with IoT Devices
To address this issue, the company has equipped their drones with IoT devices that can transmit data to the data lake in real-time. The goal is to process this raw data and perform aggregations to calculate the charge sessions, ultimately notifying drivers and stakeholders once a session has been successfully terminated.
Here's a sample of the JSON data collected from the drones:
{"UIN":"52GD2997","can_info":{"soc_percentage":82.0,"battery_temperature_high_alert":0,"soc":80.0,"propellor_speed":13.5,"cam_angle":0,"ttc_min_info":0,"key_status":0,"minimum_cell_voltage":3.3090999126434326,"dte":123.0,"pack_voltage":76.0999984741211,"ttc_hour_info":0,"ac":1,"odometer":53935.0,"minimum_cell_temperature":31.0,"device_id":"50DCB335421”,"charge_indicator":0,"maximum_cell_temperature":33.0,"time":1715227208337,"brake_pedal":0,"maximum_cell_voltage":3.31030011177063}}
This data needs to be transformed into a Spark DataFrame for further processing.
Transformed data in Spark DataFrame:
| UIN | Soc_percentage | Charge_status | time |
| 52GD2997 | 82 | 0 | 1715227208337 |
| 52GD2997 | 82 | 1 | 1715227508337 |
| 52GD2997 | 83 | 1 | 1715227808337 |
| 52GD2997 | 84 | 1 | 1715228108337 |
Case description:
.jpg)
Databricks: Smooth Ingestion and Spark-Based Use Cases
Databricks would be an excellent platform for the use case due to its scalable architecture, real-time processing capabilities, and integration with multiple data processing frameworks. Here's why:
- Scalability and Distributed Processing: Pandas DataFrames are ideal for small to medium-sized datasets but may struggle with large-scale data. Databricks provides a distributed environment with Apache Spark, which offers more efficient data processing at scale. This allows you to handle larger datasets without the serialization bottlenecks and latency issues you’re encountering with pandas.
- Real-Time Data Processing: To handle the near real-time notification for switching charge modes, Databricks supports real-time streaming using Structured Streaming. This allows you to monitor charge statuses continuously and trigger actions (like notifying users) as soon as the conditions are met, reducing delays. You can use a streaming pipeline to handle charge session data, processing it incrementally rather than waiting for batch processes to complete.
- Delta Lake for Data Integrity: Databricks' Delta Lake can enhance your current setup by enabling ACID transactions, scalable metadata handling, and time travel. You can use it to efficiently track and update charge sessions while ensuring data integrity, especially during session breaks and monitoring charge status. Delta Lake supports both batch and streaming data, making it versatile for your use case.
- Optimizing Model Performance with Feature Store: If you want to optimize drone performance further, Databricks' Feature Store can manage real-time features like charge status, drone location, and task load. These features can be accessed in both offline and online modes to support dynamic decision-making, such as terminating or continuing charge sessions based on real-time status checks.
- Event-Driven Architecture: For near real-time notification, you can leverage Databricks Jobs or Databricks SQL to run event-driven workflows. You can set up triggers that notify users if the charge status remains false during the 5-minute break or if any other key thresholds are exceeded.
- Seamless Integration: Databricks integrates with various external tools, such as messaging platforms or IoT solutions, enabling you to push real-time alerts to relevant stakeholders. You can build a system where, upon detecting anomalies in the charge session, the platform instantly sends a notification or activates an automated action.
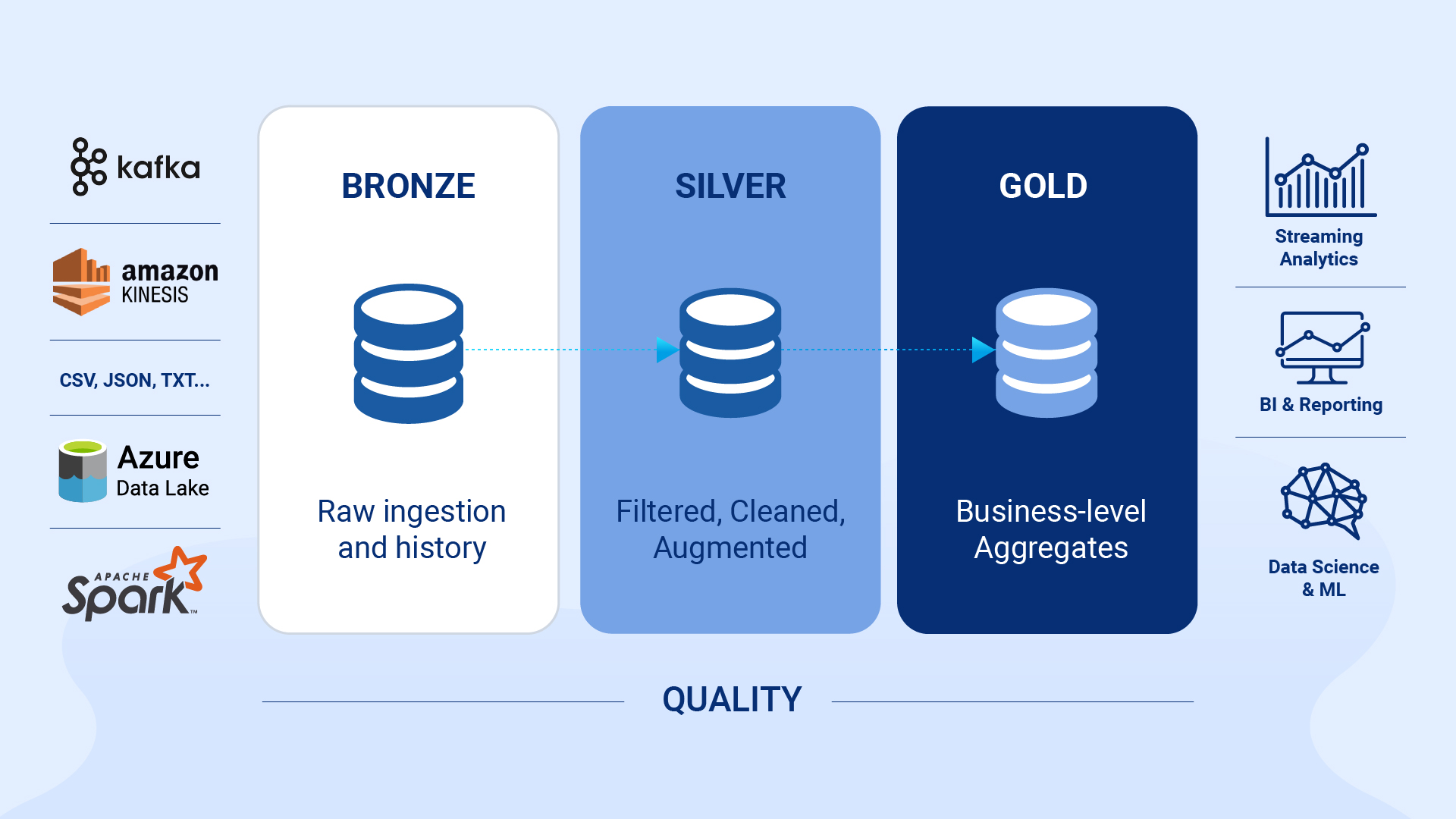
Following the medallion architecture in Databricks, load the json/csv files into delta format into the bronze layer using autoloader and proceed with the below code.
Using autoloader, we shall ingest files from the lake where IOT devices are dumping data using streaming services like Kafka.
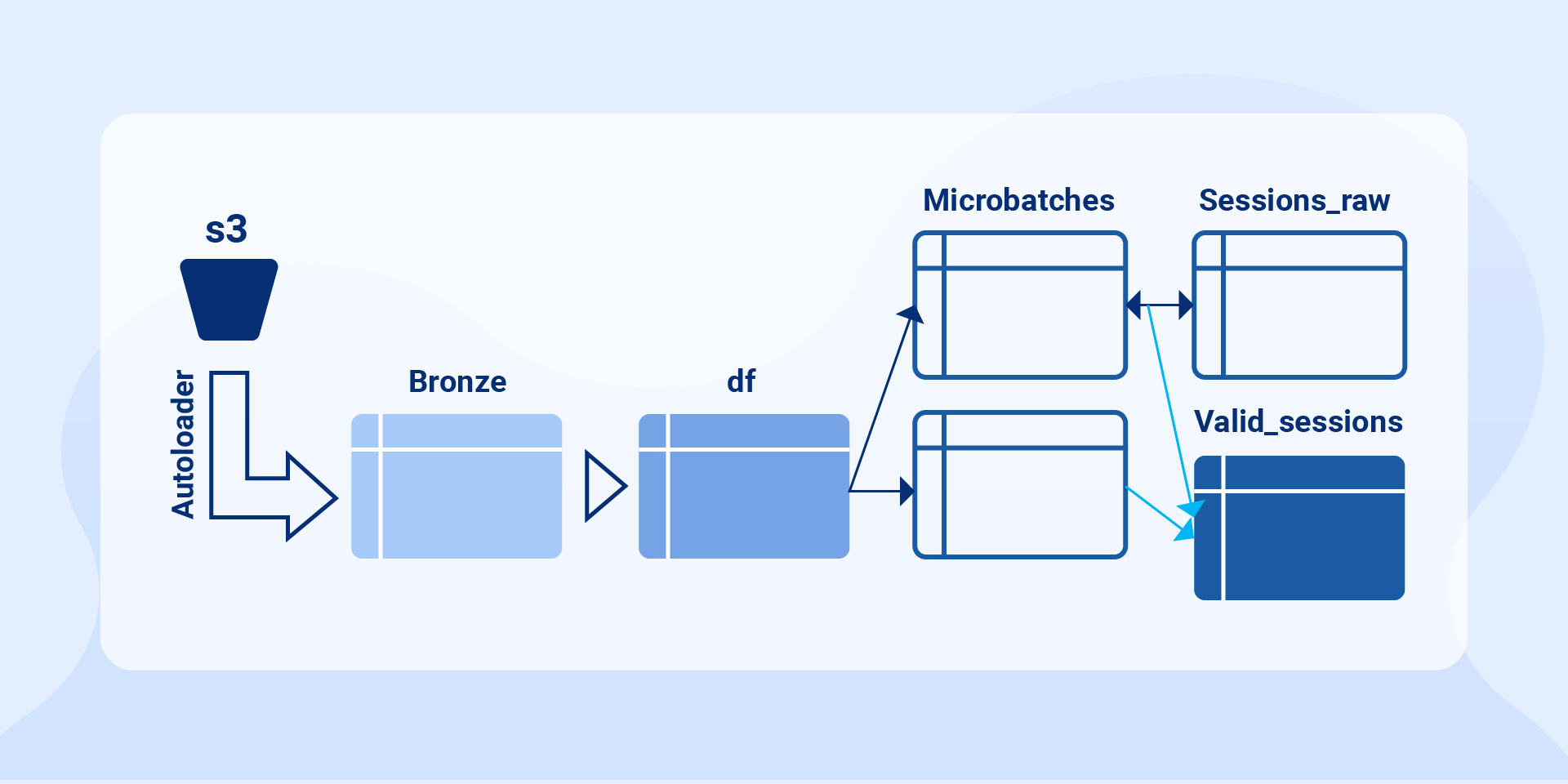
The raw data is cleaned and transformed for expected quality and stored in df which shall write its data to a delta table in silver zone.
This silver table incremental data is fetched and aggregated, transformed using the below python code.
Code:
from delta.tables import *
from pyspark.sql.types import *
from pyspark.sql.functions import *
from pyspark.sql import functions as F
from pyspark.sql.window import Window
from datetime import datetime
break_duration = 5 #Add custom break durations
session_duration=30 #add custom session duration
df = spark.read.table("<catalog>.<schema>.<table>")
# Step 1: Calculate initial `cum_sum`
window_spec = Window.partitionBy("UIN").orderBy("time")
df = df.withColumn("prev_state", F.lag("charge_state").over(window_spec)) \
.withColumn("change", F.when(F.col("charge_state") != F.col("prev_state"), 1).otherwise(0)) \
.withColumn("cum_sum", F.sum("change").over(window_spec))
display(df)
.jpg)
# Step 2: Aggregate to get `start_time`, `end_time`, and `duration`
temp1 = df.groupBy("UIN", "cum_sum", "charge_state") \
.agg(F.first("time").alias("start_time"),
F.last("time").alias("end_time")) \
.drop("cum_sum").withColumn("duration",col("end_time")-col("start_time"))
if "sessions_raw" in [table.name for table in spark.catalog.listTables("<schema>")]:
t=spark.read.table("<catalog name>.<schema>.sessions_raw")
temp1=temp1.unionAll(t)
You check for existing unfinished sessions and breaks for adjusting the microbatches.
window_spec = Window.partitionBy("UIN").orderBy("start_time")
temp2 = temp1.withColumn("prev_charge", F.lag("charge_state").over(window_spec)) \
.withColumn("next_charge", F.lead("charge_state").over(window_spec))
display(temp2)
temp3 = temp2.withColumn("charge_state", F.when(
(F.col("charge_state") == 0.0) &
(F.col("duration") < break_duration*60*1000),
F.col("prev_charge")
).otherwise(F.col("charge_state")))
temp3 = temp3.withColumn("prev_charge", F.lag("charge_state").over(window_spec)) \
.withColumn("next_charge", F.lead("charge_state").over(window_spec))
df_with_change = temp3.withColumn("change", F.when(
F.col("charge_state") != F.col("prev_charge"), 1
).otherwise(0)).withColumn("cum_sum", F.sum("change").over(window_spec))
temp4 = df_with_change.groupBy("UIN", "charge_state", "cum_sum") \
.agg(F.min("start_time").alias("start_time"),
F.max("end_time").alias("end_time"),
F.sum("duration").alias("duration"))
temp5 = temp4.withColumn("next_duration", F.lead("duration").over(window_spec)).withColumn("next_state", F.lead("charge_state").over(window_spec)).withColumn("next_2_state", F.lead("charge_state", 2).over(window_spec)).withColumn("prev_state", F.lag("charge_state").over(window_spec))
display(temp5)
.jpg)
The highlighted field is converted to 1 from 0 since the duration was less than the threshold
result = temp5.withColumn("status", F.when(
(F.col("charge_state") == 1.0) &
(F.col("next_state") == 0.0) &
(F.col("next_2_state") == 1.0) &
(F.col("next_duration") > break_duration*60*1000), "completed")
.when((F.col("charge_state") == 0.0) &
(F.col("next_state").isNotNull()), "delete")
.when((F.col("charge_state") == 0.0) &
(F.col("duration")>=break_duration*60*1000), "delete")
.when((F.col("charge_state") == 0.0) &
(F.col("prev_state").isNull()), "delete")
.otherwise(None))
sessions_raw = result.filter(col("status").isNull()).orderBy("UIN", "start_time").select("UIN","charge_state","start_time","end_time","duration")
sessions_raw.dropDuplicates().write.mode("overwrite").saveAsTable("("<catalog>.<schema>.sessions_raw")
display(sessions_raw)
Cases:
- The previous and next session had state 1 and break duration is greater then threshold, we mark the previous session as complete
- If the break duration has exceeded the threshold, and complete has been marked, lets mark status as delete
- The previous session is not known, in this case we mark the off charge session to be delete
You can modify the cases as per business requirements
final_df = result.filter((col("status") == 'completed') &
(col("duration") >= session_duration * 60 *
1000)).select("UIN","start_time","end_time","duration")
final_df.dropDuplicates().write.mode("append").saveAsTable("<catalog>.<schema>.valid_sessions")
Considering the above logic, there are multiple aggregates which are not compatible with streaming.
Here comes micro-batching!
We will call Spark’s inbuilt function for each batch to create micro batches and trigger the above logic appending to the final gold table.
df = spark.readStream.table("<catalog>.<schema>.<table_name>")
df.writeStream.option("checkpointLocation", checkpoint_path).foreachBatch(process_batch).start()
Here, the process batch function calls the above code, which accepts two parameters:
- df
- epoch_id
DroneX could benefit from this approach, as it could enable them to proactively monitor and optimize the performance of their drones, leading to increased efficiency and cost savings. Thus, streaming jobs for sessionization can enable continuous updates of data and provide real-time insights, amplifying customer experience, and driving business growth. They reduce processing time and provide timely actionable information, making them an essential component in today's data-driven world.
Posted on : September 17, 2024
Category : Data Engineering
About the Authors

Harsh Bhandari
 LinkedIn
LinkedIn