The author is a Senior Data Engineer in Eucloid. For any queries, reach out to us at: contact@eucloid.com
Personalization That Keeps Customers Coming Back: Built on Databricks

We live in an era of instant gratification. From WhatsApp messages to Instagram videos, attention spans are shorter than ever. Moreover, customers expect immediate, personalized interactions at every touchpoint.
.jpg)
But for our client, a leading online platform, fragmented data and slow, manual processes stood in the way. User profiles, behavioral logs, and transaction data lived in fragmented systems, and marketing actions were often manual, or batch driven. This made it impossible to respond in real time with relevant, engaging content.
In this world of urgent expectations, we knew our client needed a system that could recognize user intent the instant they logged in and respond with offers and experiences that felt just right, right then. Thanks to Databricks’ unified Lakehouse platform, we could turn this vision into reality!
The Challenge: Siloed Data and Slow Decisions
Our client’s legacy environment had multiple pain points:

- Fragmented data across systems: User activity, CRM records, and product catalogs were scattered in separate databases and files. This made it hard to compute features consistently or see the full picture of each user.
- Delayed, manual workflows: Decisions like generating recommendations or promotions were done offline or with batch jobs. By the time insights surfaced, they were stale.
- No real-time personalization: The website couldn’t adapt dynamically to each customer session. Every user essentially saw the same experience at login.
- Lack of unified feature store: Without a central feature repository, data science teams struggled to reuse or even find the right data. Models were trained on inconsistent feature definitions.
- Scaling bottlenecks: During peak traffic, the old system creaked. It wasn’t built to handle millions of users logging in simultaneously. These challenges meant the client was missing out on revenue and engagement opportunities from timely personalization.
Our Databricks-Powered Solution
To address these hurdles, we architected an end-to-end real-time personalization pipeline on the Databricks Lakehouse. Our solution looked like this:
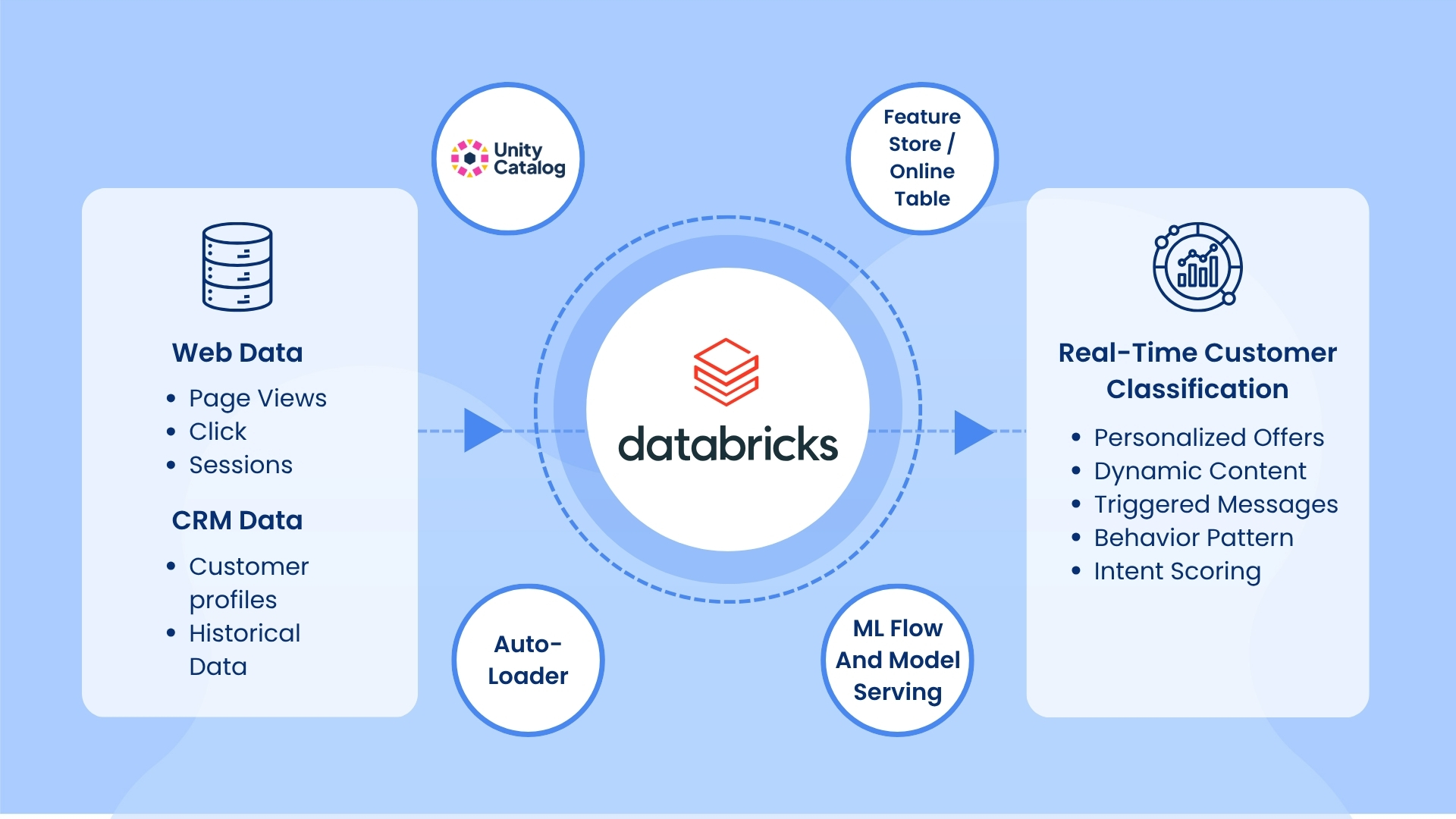
Streaming Data Ingestion:
We used Databricks Auto Loader to continuously ingest login and clickstream events as they occurred. Auto Loader watched a cloud storage location and processed new data files in near real time, scaling to millions of files per hour. Each login event became a row in a Delta Lake table as soon as it happened.
Unified Feature Store:
All user profiles, behavioral features, and session metrics were stored in Delta tables under Unity Catalog. This meant features were centrally defined and versioned. Crucially, we used Databricks Online Tables: read-optimized, low-latency copies of our feature tables. These online tables allowed our models to fetch the latest feature values instantly at scoring time. Because they were serverless and auto-scaling, they provided high-throughput, sub-millisecond lookups even for millions of users.
Model Training & Serving:
We trained XGBoost models on a combination of historical data and recent streaming sessions to predict user intent (e.g. next-best offer, product affinity, or churn risk). The models were tracked in MLflow and registered in Unity Catalog’s Model Registry, bringing centralized version control, lineage, and governance.
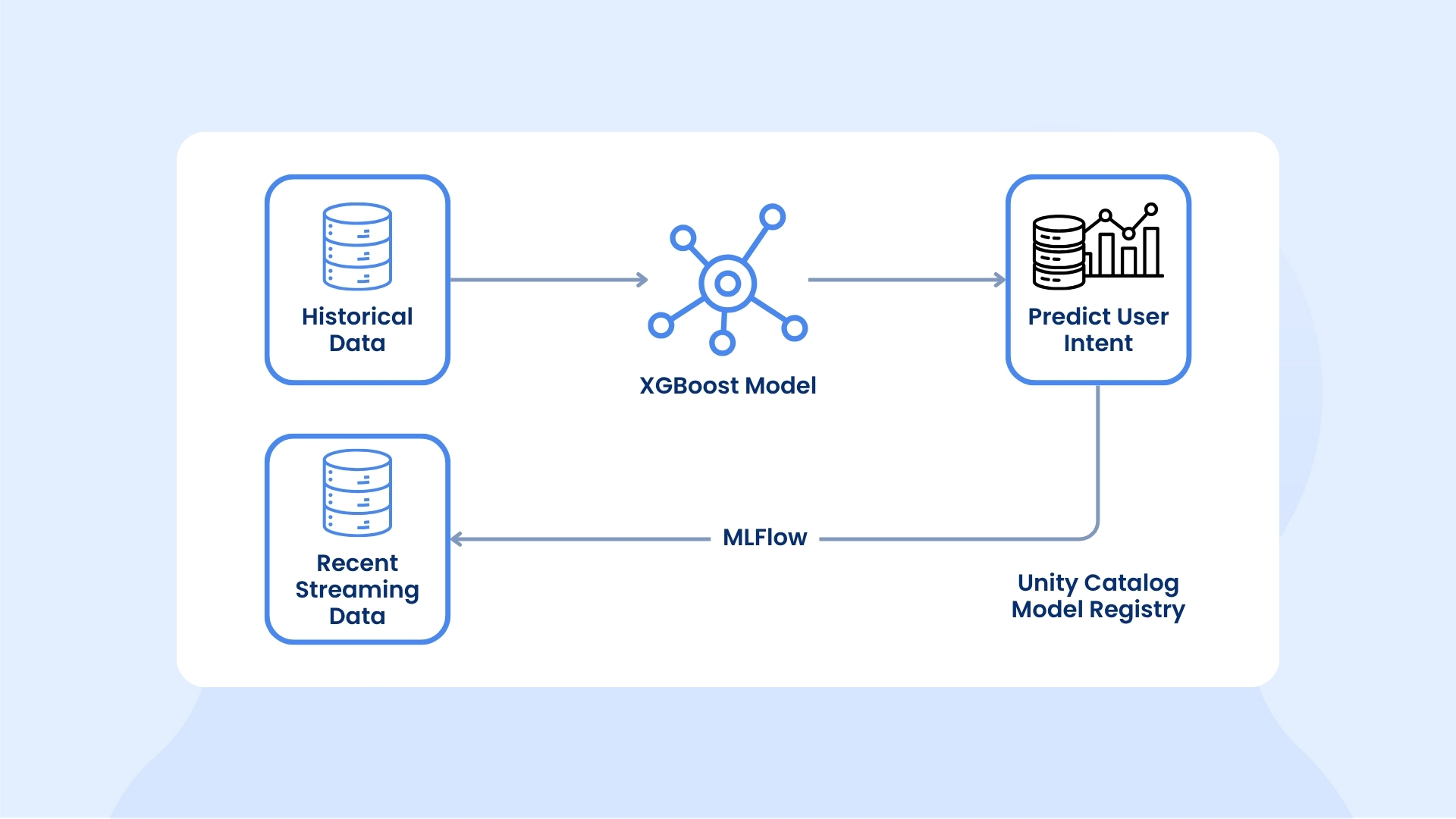
We then deployed these models using MLflow Model Serving as persistent REST endpoints. These endpoints automatically served new model versions and supported automatic feature lookups from our online tables. In practice, when a login event arrived, the serving endpoint queried the registered model and Databricks fetched all needed features from the online tables behind the scenes.
Real-Time Inference:
The ingestion of a login event (via Auto Loader) triggered a Structured Streaming job. This job assembled the feature vector for the user (merging static and dynamic attributes) and called the MLflow endpoint for a prediction. Databricks Structured Streaming was optimized for sub-second latency; studies showed it could achieve end-to-end latencies as low as 150–250 ms even at high volume. As a result, our inference pipeline routinely returned predictions in under 1 second from event ingestion.
High Scalability & Governance:
Because we built on Databricks’ serverless and auto-scaling infrastructure, the system handled traffic spikes elastically. During high concurrency, the online tables and model serving nodes automatically scaled out without manual intervention. At the same time, Unity Catalog ensured full governance: access control, auditing, and lineage for every piece of data and every model artifact. This end-to-end observability gave the business confidence in both compliance and model accuracy.
Together, these components created a seamless, automated pipeline.
When a customer logs in, Auto Loader ingests that event, the streaming engine fetches up-to-date features, the MLflow endpoint scores the model, and the prediction (say, “offer a 20% discount” or “recommend product X”) is sent back through an API. The website then uses that prediction to personalize the UI – all in about one second.
.jpg)
Key Benefits and Business Impact
The new Databricks-based solution delivered immediate value across the organization:
.jpg)
Instant Personalized Decisions:
Every user login now triggers a personalized action in real time. Offers, promotions, and content are tailored on-the-fly to each customer’s profile and behavior. This sub-second intelligence was only possible because our pipeline is built for speed – MLflow model endpoints serve predictions as REST calls and Spark Structured Streaming supports sub-second processing. The result: customers see contextually relevant experiences the moment they arrive, vastly improving engagement.
ML-Powered at Scale:
By unifying features and models in Databricks, we scaled AI across the platform. Millions of users are served concurrently, and new models (e.g. segmentation or product affinity models) can be deployed with minimal effort. The data science team can train on fresh data continuously and push updated models into production via MLflow, without bottlenecks. Automated feature lookups mean our scientists don’t have to manually code data joins – the system does it automatically.
Fully Automated Workflow:
Gone are the days of manual dashboards or batch job runs. Every stepm from event ingestion to scoring to action, is automated in Databricks Jobs and Workflows. This eliminates human delays and errors. As soon as a model improvement is logged in MLflow, it can be immediately serving new predictions. Similarly, as new behavioral data streams in, our features in Unity Catalog are updated, keeping the intelligence current.
Elastic Performance Under Load:
Using Databricks’ serverless model serving and Unity Catalog’s online tables, the system simply ups its capacity when needed. For example, during peak traffic the Auto Loader stream partitioned gracefully, and the online tables spun up more compute to handle more lookups. This means whether 1,000 or 1,000,000 users log in at once, the latency stays consistently low.
Unified Governance and Observability:
With Unity Catalog, everything is audited and discoverable. Analysts can trace a prediction back to the exact model version and feature values used. Security teams have a single pane of glass to manage data permissions across the lakehouse. This built-in governance simplifies compliance reporting and model debugging, giving stakeholders confidence in the end-to-end pipeline.
Outcome: Smarter Engagement in Real Time
The transformation was dramatic. Our client can now detect user intent and session patterns immediately at login.
For example, if a user frequently browses winter jackets, the system can instantly prioritize related product recommendations or promotions on the home page. If a long-time customer hasn’t made a purchase recently, the model might trigger a special loyalty offer the moment they sign in. All such contextual actions are calculated on the spot.
.jpg)
We made sure everything was connected, from the moment someone logs in to when they see personalized offers on the website: so, it all just works together seamlessly. The marketing team reports that personalized offers are now delivered with no perceptible lag, and they can launch new targeted campaigns rapidly (simply by updating the model or rules and letting the system run).
Customer engagement metrics rose as more visitors received relevant content immediately. In short, Databricks turned raw event data into real-time intelligence: personalization that happens live and at scale.
We unified real-time streams, feature data, models, and governance on the Databricks Lakehouse. This gave the client lightning-fast personalization. The entire decision pipeline runs in about a second. The business can now respond to customer behavior instantly. The result? Higher conversion rates. Happier customers. A real competitive edge in today’s digital world.
.jpg)
Thus, raw data became more than numbers; it became a spark for meaningful, real-time conversations with every user, governed end-to-end.
Ready to turn fragmented data into real-time, personalized experiences? At Eucloid, we specialize in designing and implementing Databricks solutions that bring instant intelligence to every user interaction. Let’s chat about how we can help you transform your data into a competitive advantage. Reach out at databricks@eucloid.com to get started.
Posted on : June 04, 2025
Category : Data Engineering
About the Authors

Vikramjit Singh