The author is a Senior Data Consultant in Eucloid. For any queries, reach out to us at: contact@eucloid.com
From Cloud Chaos to Clarity: Rethinking Your Migration Strategy

Let’s be honest. Cloud data platforms have transformed how businesses manage and scale data. But as organizations grow, so do the demands on their data infrastructure.
What once felt streamlined can start to feel fragmented: pipelines scattered across tools, rising operational overhead, and performance tuning that eats into agility. Over time, even the most well-intentioned architectures can begin to show their limits.

You didn’t move to the cloud for complexity. You moved for speed, scale, and flexibility. But now, the question is: how do you realign your data foundation to keep up with what the business needs next?
That’s why rethinking your approach to cloud data migration isn’t just timely, it’s strategic.
The Real Problem with Most Cloud Migrations
Cloud-to-cloud migrations are rarely just about changing vendors. Done right, they unlock operational agility, cost optimization, and stronger data governance. Done wrong, they lead to: 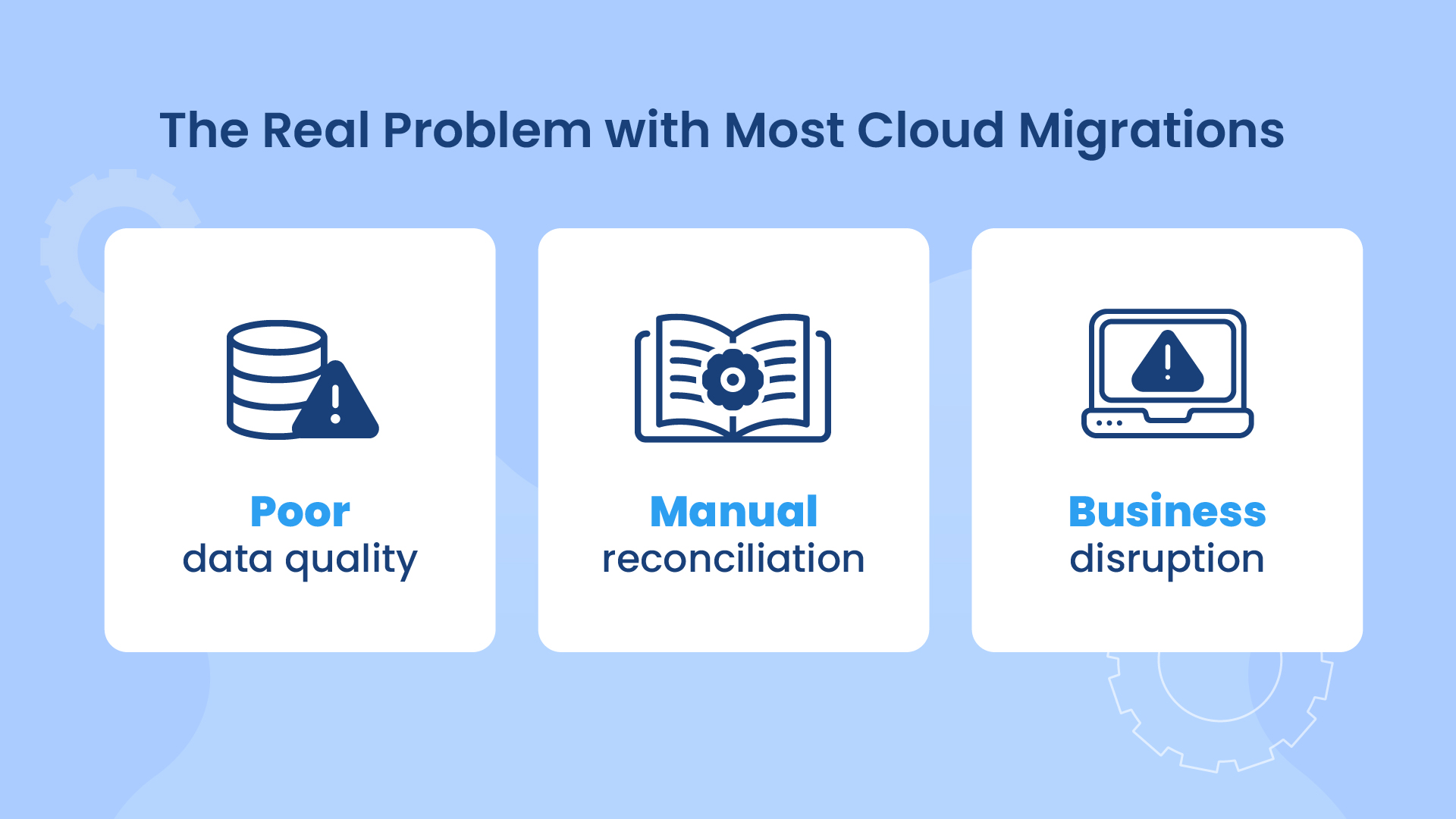
- Inconsistent, incomplete, or inaccurate data can hinder migration efforts and lead to unreliable insights
- Traditional reconciliation processes are time-consuming, error-prone, and lack the scalability to handle large data volumes
- Data discrepancies can lead to significant business disruptions, regulatory compliance issues, and financial losses
Moreover, migrations often stretch across quarters, hampering analytics programs and straining cross-functional teams.
What If Migration Could Be Smarter, Not Just Faster?
Most enterprises treat migration as a one-time data lift. But what if it was an opportunity to redesign your foundation: to clean up legacy, unify scattered workloads, and enable faster analytics downstream?
This is the shift our migration framework brings.
Here’s How We Approach It:
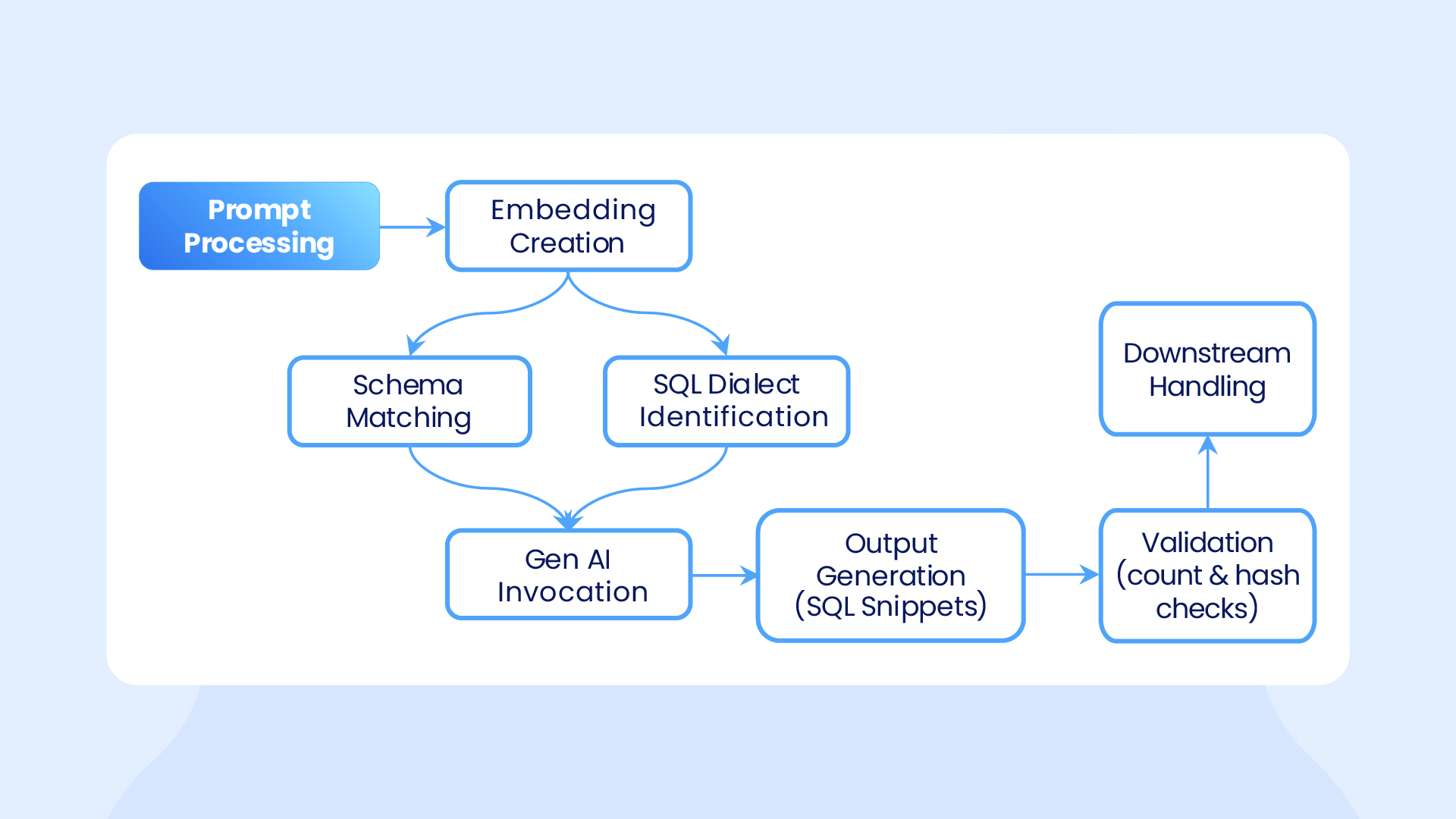
1. Smart, GenAI-Powered Discovery and Query Conversion
We begin by systematically mapping all tables, queries, procedures, and data lineage across SQL dialects and platforms to build a comprehensive understanding of the migration landscape. Using large language models such as OpenAI and Claude, we automate the conversion of simple to moderately complex queries across dialects.
This automation minimizes manual effort and reduces the likelihood of errors, allowing data engineering teams to focus on more complex logic. The approach delivers a scalable solution that supports multiple SQL formats and drives a 20–30% reduction in overall migration timelines.
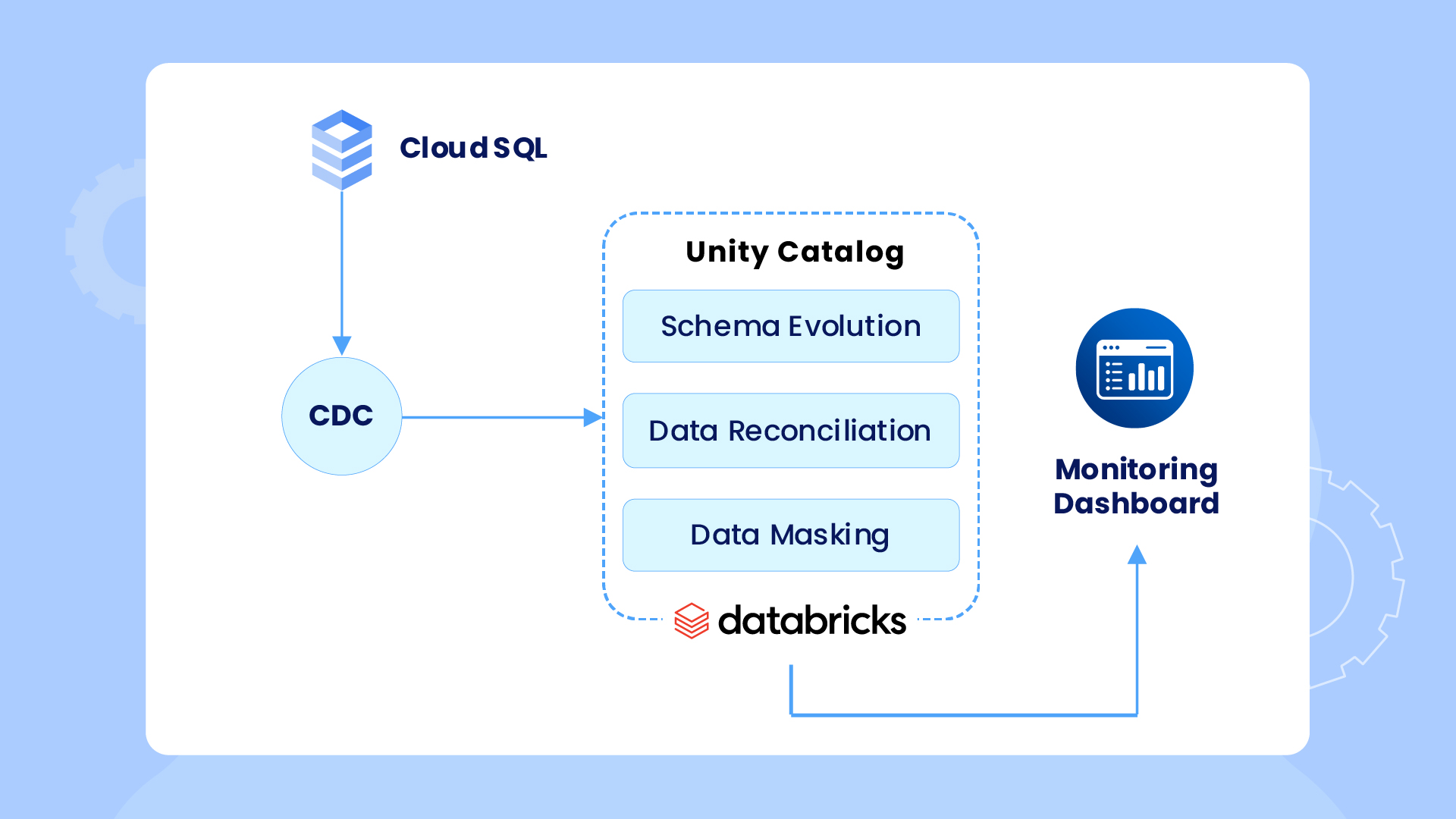
2. Accelerated Ingestion with Built-In Change Tracking
Our SQL ingestion accelerator enables real-time CDC (change data capture) from any SQL warehouse to Databricks, ensuring timely updates, not just snapshots, are captured for analytics and ETL.
It automates schema evolution, so structural changes are seamlessly reflected in Databricks. With built-in reconciliation, monitoring dashboards, and simplified data masking, it ensures accurate, secure, and compliant data pipelines with minimal manual effort.
3. Data Reconciliation Framework
We’ve developed an in-house robust three-dimensional reconciliation and UAT framework that ensures data integrity across three critical dimensions:
- Schema Validation – Verifies structural compatibility between source and target systems to prevent data truncation or loss during transfer
- Data Count Validation – Verifies records in both systems within the Lakehouse to identify data loss and/or duplication.
- Row-Level Hash Validation – Detects transformation errors and corruption through granular, row-wise hash comparisons.

Powered by Delta Lake’s schema flexibility and Spark’s distributed processing, the framework efficiently handles large-scale validation tasks, ensuring reliable, high-performance reconciliation directly within the Databricks Lakehouse.
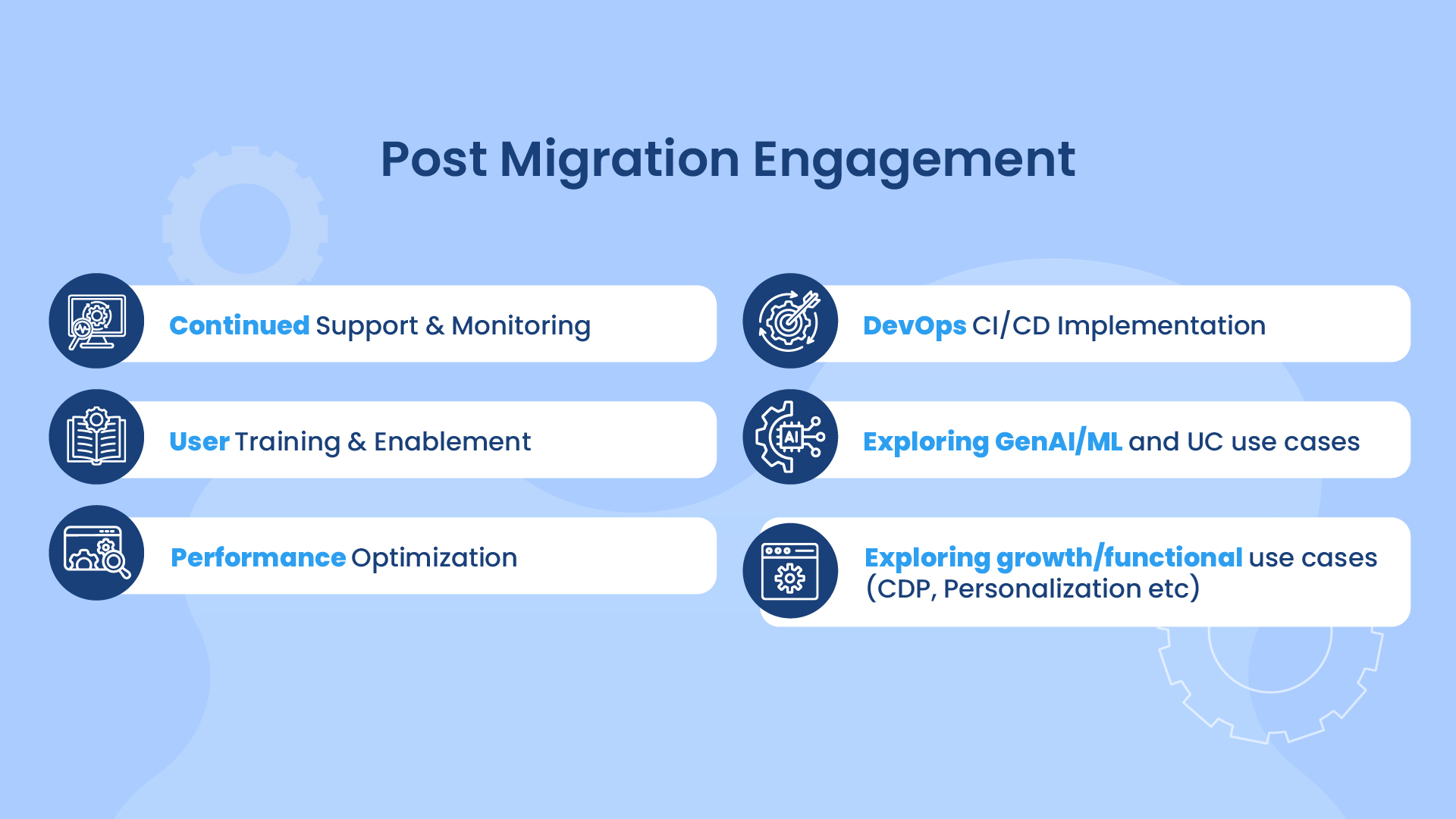
4. Post Migration Engagement:
We continue to partner with clients beyond migration to ensure long-term success. We provide detailed documentation, proactive troubleshooting, and hands-on support to address emerging needs.
This includes user training and enablement, performance tuning, and DevOps/CI-CD implementation. We also collaborate on exploring advanced use cases such as GenAI, ML, and Unity Catalog, while helping clients unlock further value through growth-focused initiatives like Customer Data Platforms (CDPs), personalization, and other functional analytics use cases.
Databricks: The Foundation for a Better Migration Outcome
At the heart of this approach lies Databricks, a platform purpose-built for modern data engineering. Here’s what makes it stand out:
1. Unified Lakehouse Architecture
- Combines the best of data lakes and data warehouses, enabling seamless handling of structured and unstructured data.
- Supports diverse workloads, including batch processing, streaming, machine learning, and business intelligence, all within a single platform.
2. Simplified Data Management
- Provides a single source of truth, reducing data silos and ensuring consistency across the organization.
- Facilitates real-time data processing and analytics, enhancing decision-making capabilities.
3. Advanced Governance with Unity Catalog
- Offers fine-grained access controls and auditing capabilities, ensuring data security and compliance.
- Simplifies data discovery and lineage tracking, aiding in regulatory adherence and data quality management.
4. Declarative Data Pipelines with Delta Live Tables
- Enables the creation of reliable and maintainable data pipelines using a declarative approach.
- Automates error handling, monitoring, and recovery, reducing operational overhead.
5. Scalability and Performance
- Built on Apache Spark, Databricks offers high-performance processing for large-scale data workloads.
- Its cloud-native architecture allows for elastic scaling, accommodating varying data processing demands efficiently.
6. Integration with Existing Tools
- Supports seamless integration with popular data tools and platforms, preserving existing investments and workflows.
- Facilitates a smoother transition during migration by minimizing disruptions to current operations.
7. Cost Efficiency
- Offers a lower total cost of ownership by consolidating multiple data processing needs into a single platform.
- Reduces infrastructure and maintenance costs through its unified approach.
8. Future-Ready Platform
- Continuously innovates with features supporting advanced analytics, AI, and machine learning.
- Ensures that organizations are equipped to handle evolving data challenges and opportunities.
And because it’s open and modular, Databricks works well with your existing tools— from Fivetran and DBT to Airflow and Hightouch.
Real Impact, Proven at Scale
Whether it was migrating 2500+ BigQuery models and 50TB of data for a SaaS leader, or replatforming Azure Databricks to GCP Databricks for a global ad-tech firm, our methodology has delivered:
- Up to 30% cost optimization
- 20%+ performance gains
- 99% automated data reconciliation
- POC flexibility across Unity Catalog and GenAI-based validation
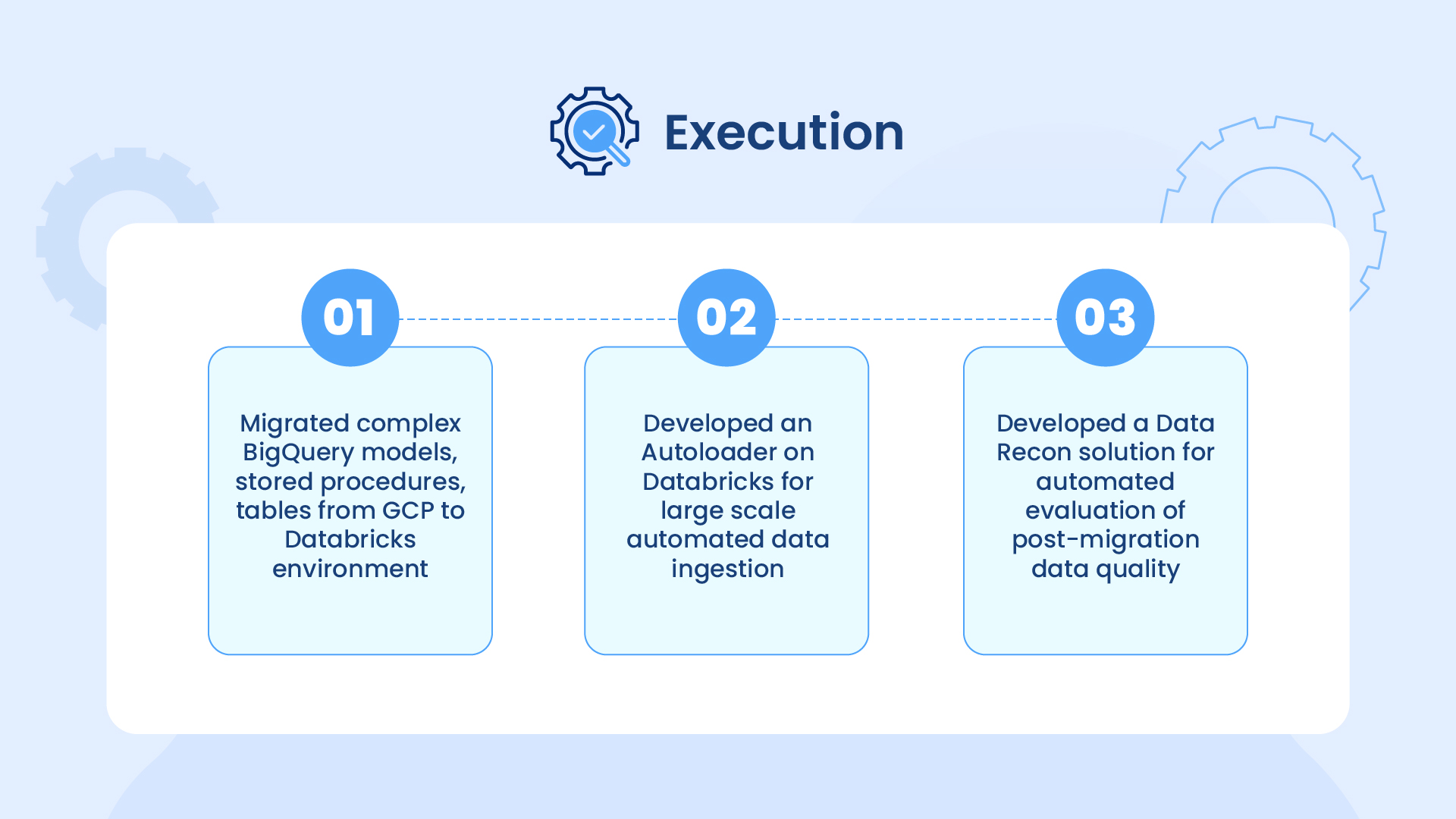
These weren’t just migrations. They were full-fledged data modernizations, unlocking cleaner pipelines, smarter governance, and faster analytics delivery.
A migration isn’t just a move, it’s a moment. A moment to simplify. To consolidate. To lay the groundwork for analytics that scale with your business. It’s also the foundation for streamlining machine learning use cases, which is one of the key advantages of migrating to Databricks. With everything unified in a single data source, organizations benefit from both scalability and faster time-to-value.
We’ve worked with some of the world’s most data-intensive enterprises to do exactly that. And while no two journeys are the same, the north star remains constant: clarity over complexity, outcomes over overhead.
At Eucloid, we help enterprises migrate and modernize on Databricks: faster, cleaner, and with less risk. Get in touch at databricks@eucloid.com to explore how we can support your next move.
Posted on : May 22, 2025
Category : Data Engineering
About the Authors

Ankit Kalra
 LinkedIn
LinkedIn